أذكر جيدًا ذاك اليوم في مكتبي الصغير، قبل سنوات قليلة، حين كانت نماذج اللغة مجرد فكرة نظرية نتحدث عنها في المنتديات. كنت أعمل على نظام تحليل مشاعر بسيط، وكان الأمر معقدًا ويتطلب الكثير من القواعد اليدوية. في ذلك المساء، وقعت عيني على ورقة بحثية تتحدث عن نموذج اسمه GPT-2. قرأت عنه بفضول وشك، فكرة أن يكتب الكمبيوتر نصًا إبداعيًا بدت لي ضربًا من الخيال.
بعد بضعة أشهر، أتيحت لي فرصة تجربة GPT-3 لأول مرة عبر واجهة برمجية (API). قلت في نفسي، “خلّينا نشوف شو قصة هالنموذج الخُرافي”. كتبت له أمرًا بسيطًا: “اكتب قصيدة قصيرة عن شجرة زيتون صامدة في وجه الريح”. خلال ثوانٍ، ظهرت أمامي كلمات لم أكن أتوقعها من آلة. وصفت الشجرة بجذورها المتشبثة بالأرض، وأغصانها التي تروي قصة أجيال. شعرت بقشعريرة. لم تكن مجرد كلمات مرصوفة، بل كان فيها روح.
لكن عندما طلبت منه كتابة كود Python يستخدم مكتبة فلسطينية غير مشهورة، ارتبك وأعطاني “هلوسات” برمجية لا معنى لها. هنا كانت لحظة “الأها!” بالنسبة لي. هذه النماذج ليست سحرًا، بل هي تقنية معقدة لها قواعدها ونقاط قوتها وضعفها. ومنذ ذلك اليوم، كرست جزءًا كبيرًا من وقتي لفهم هذه “العقول” الرقمية، وكيف يمكننا كمطورين أن نروّضها ونستخدمها لبناء أشياء عظيمة. في هذا الدليل، سآخذكم في رحلة من الألف إلى الياء، من فهم قلب هذه النماذج النابض، إلى بناء مساعد ذكي خاص بكم. يلا نبدأ.
ما هي نماذج اللغة الكبيرة (LLMs)؟
ببساطة شديدة، نموذج اللغة الكبير (Large Language Model) هو برنامج ذكاء اصطناعي ضخم، تم تدريبه على كمية هائلة من النصوص والبيانات (تقريبًا كل ما هو مكتوب على الإنترنت). الهدف من هذا التدريب هو “فهم” اللغة البشرية، ليس فقط ككلمات وقواعد، بل كأنماط وعلاقات وسياقات.
تخيله كطالب قرأ كل كتاب في أكبر مكتبة في العالم. هذا الطالب لا يحفظ الكتب كلمة بكلمة، بل يستوعب الأفكار، وأساليب الكتابة، والعلاقات بين المفاهيم. عندما تسأله سؤالًا، فإنه لا ينسخ إجابة من كتاب معين، بل “يؤلف” إجابة جديدة بناءً على كل المعرفة التي استوعبها. هذا بالضبط ما يفعله الـ LLM: يتنبأ بالكلمة (أو الجزء من الكلمة) التالية الأكثر منطقية في تسلسل معين، بناءً على الأنماط التي تعلمها.
يُقاس حجم وقوة هذه النماذج بعدد “المعلمات” (Parameters) التي تحتويها، والتي يمكن اعتبارها كالمشابك العصبية في الدماغ. النماذج الحديثة تحتوي على مئات المليارات من المعلمات، مما يمنحها قدرة مذهلة على الفهم والتوليد.
كيف تفهم الآلة؟ معمارية Transformers وآلية الانتباه
السر وراء القفزة النوعية في نماذج اللغة هو معمارية تسمى “Transformers”، والتي تم تقديمها في ورقة بحثية ثورية عام 2017 بعنوان “Attention Is All You Need”. قبلها، كانت النماذج (مثل RNNs) تقرأ النص كلمة بكلمة بالترتيب، مما كان يسبب مشكلة “فقدان الذاكرة” في الجمل الطويلة.
الـ Transformers غيرت اللعبة بالكامل من خلال مفهوم آلية الانتباه (Attention Mechanism).
فكر فيها هكذا: عندما تقرأ جملة “القط جلس على السجادة لأنه كان متعبًا”، فإن عقلك يربط كلمة “لأنه” بـ “القط” وليس “السجادة”. أنت “تنتبه” إلى الكلمات الأكثر صلة ببعضها البعض لفهم المعنى. آلية الانتباه تفعل الشيء نفسه، حيث تسمح للنموذج بالنظر إلى كل الكلمات في الجملة دفعة واحدة، وتحديد “وزن” أو أهمية كل كلمة بالنسبة للكلمات الأخرى. هذا يسمح له بفهم العلاقات المعقدة والسياقات الطويلة، وهو ما كان مستحيلًا تقريبًا في السابق.
نصيحة من أبو عمر: لا تخف من المصطلحات المعقدة. لست بحاجة إلى فهم الرياضيات وراء آلية الانتباه لتستخدمها. يكفي أن تفهم فكرتها الأساسية: هي الطريقة التي يحدد بها النموذج الكلمات المهمة في النص ليفهم السياق بشكل أفضل.
من طالب مجتهد إلى خبير: مراحل تدريب نماذج اللغة
يمر أي LLM قوي بمرحلتين رئيسيتين من التعلم، تليها طرق تخصيص متقدمة.
المرحلة الأولى: التدريب المسبق (Pre-training)
هنا يتم بناء الأساس المعرفي. يتم تدريب النموذج على مجموعة بيانات ضخمة جدًا ومتنوعة (كتب، مقالات، ويكيبيديا، كود برمجي، محادثات…). الهدف ليس تعليمه مهمة محددة، بل تعليمه “اللغة” نفسها: القواعد، بناء الجمل، الحقائق العامة عن العالم، المنطق، وحتى أساليب الكتابة المختلفة. هذه العملية مكلفة جدًا وتتطلب قوة حاسوبية هائلة (آلاف من وحدات معالجة الرسوميات GPU لأسابيع أو أشهر).
المرحلة الثانية: الضبط الدقيق (Fine-tuning)
بعد أن أصبح لدينا نموذج بمعرفة عامة واسعة، يمكننا “تخصيصه” ليصبح خبيرًا. الـ Fine-tuning هو عملية إعادة تدريب النموذج على مجموعة بيانات أصغر وأكثر تخصصًا. على سبيل المثال:
- لإنشاء chatbot متخصص في الدعم الفني، نقوم بعمل Fine-tuning على آلاف المحادثات السابقة بين العملاء وفريق الدعم.
- لإنشاء مساعد قانوني، نقوم بعمل Fine-tuning على مجموعة كبيرة من الوثائق والقضايا القانونية.
هذا يجعله “خبيرًا” في مجاله، ويستخدم المصطلحات الصحيحة، ويقدم إجابات أكثر دقة وصلة بالموضوع.
| المقارنة | التدريب المسبق (Pre-training) | الضبط الدقيق (Fine-tuning) |
|---|---|---|
| الهدف | بناء معرفة عامة واسعة وفهم اللغة | التخصص في مهمة أو مجال معين |
| حجم البيانات | ضخم جدًا (تيرابايت من النصوص) | صغير ومستهدف (مئات أو آلاف الأمثلة) |
| التكلفة | باهظة جدًا (ملايين الدولارات) | معقولة نسبيًا |
| النتيجة | نموذج أساسي (مثل GPT-3) | نموذج متخصص (مثل chatbot خدمة العملاء) |
فن الحوار مع الآلة: هندسة الأوامر والسياق
هنا يبدأ الجزء العملي والممتع للمطورين. التفاعل مع الـ LLMs لا يشبه استدعاء دالة عادية، بل هو أشبه بالحوار الذي يتطلب فهمًا لآلية عمله.
الذاكرة قصيرة المدى: فهم السياق (Context) والـ Tokens
من أهم المفاهيم التي يجب أن تستوعبها كمطور: الـ LLMs ليس لديها ذاكرة حقيقية بين الطلبات. كل طلب API ترسله هو طلب مستقل تمامًا.
إذن، كيف نتذكر المحادثة؟ الجواب هو السياق (Context Window). عندما تبني chatbot، فإن مسؤوليتك هي أن تقوم في كل مرة بإرسال سجل المحادثة بالكامل (أو جزء منه) مع سؤال المستخدم الجديد. النموذج يقرأ كل هذا السياق ليفهم أين وصل الحوار، ثم يولد الرد.
هذا السياق له حجم محدود يُقاس بالـ Tokens (التوكنز). التوكن ليس بالضرورة كلمة واحدة، فكلمة معقدة قد تكون عدة توكنز. كمثال تقريبي في اللغة الإنجليزية، 100 توكن تساوي حوالي 75 كلمة. إذا تجاوزت المحادثة حجم السياق، يبدأ النموذج في “نسيان” أقدم أجزاء المحادثة.
هندسة الأوامر (Prompt Engineering): عصاتك السحرية
جودة إجابة النموذج تعتمد بشكل مباشر على جودة سؤالك (الـ Prompt). هندسة الأوامر هي فن وحرفة صياغة المدخلات للحصول على أفضل مخرجات ممكنة. إليك بعض الاستراتيجيات الفعالة:
- كن محددًا وواضحًا: لا تقل “اكتب عن السيارات”، بل قل “اكتب مقالًا من 3 فقرات للمبتدئين عن الفرق بين محركات البنزين والديزل”.
- حدد الشخصية (Persona): “أنت خبير تسويق رقمي. اكتب لي 3 أفكار لمنشورات على انستغرام لمتجر يبيع القهوة المختصة.”
- أعطِ أمثلة (Few-shot Prompting): قدم للنموذج مثالًا أو اثنين على ما تريده بالضبط. هذا يساعده على فهم النمط المطلوب.
- اطلب منه التفكير خطوة بخطوة (Chain of Thought): إذا كانت المهمة معقدة، اطلب منه “فكر خطوة بخطوة” قبل إعطاء الإجابة النهائية. هذا يحسن من جودة التفكير المنطقي لديه.
- استخدم التوجيهات السلبية: “لخص النص التالي وتجنب استخدام المصطلحات التقنية المعقدة.”
لنطبق عملياً: بناء Chatbot ذكي بـ Python
حان وقت كتابة الكود. سنبني chatbot بسيطًا يتذكر المحادثة، ثم ننتقل إلى مفهوم أكثر تقدمًا وهو RAG.
الخطوة 1: تجهيز البيئة ومفتاح OpenAI API
أولًا، ستحتاج إلى تثبيت مكتبة OpenAI في بيئة Python الخاصة بك:
pip install openaiبعد ذلك، ستحتاج إلى إنشاء حساب على منصة OpenAI والحصول على مفتاح API خاص بك. احتفظ به في مكان آمن ولا تشاركه أبدًا. من الأفضل دائمًا تحميل المفتاح من متغيرات البيئة.
الخطوة 2: أول حوار مع ChatGPT
لنقم بإجراء أول محادثة بسيطة. قم بإنشاء ملف main.py.
import os
from openai import OpenAI
# من الأفضل دائمًا تحميل المفتاح من متغيرات البيئة بدلاً من كتابته مباشرة في الكود
# في الطرفية (Terminal) استخدم الأمر: export OPENAI_API_KEY='sk-...'
client = OpenAI(api_key=os.environ.get("OPENAI_API_KEY"))
response = client.chat.completions.create(
model="gpt-3.5-turbo", # يمكنك استخدام gpt-4-turbo إذا كان متاحًا لديك
messages=[
{"role": "system", "content": "أنت مساعد ذكي ومفيد يقدم شروحات مبسطة."},
{"role": "user", "content": "اشرح لي مفهوم الـ API وكأني طفل في العاشرة من عمري."}
]
)
print(response.choices[0].message.content)
في هذا الكود، قائمة messages هي قلب الحوار:
role: "system": يحدد هوية وسلوك المساعد. هذه رسالة توجيهية للنموذج تبقى في الخلفية.role: "user": هو ما يكتبه المستخدم.role: "assistant": (سنراه لاحقًا) هو رد النموذج السابق.
الخطوة 3: بناء ذاكرة للمحادثة (إدارة السياق)
لجعل الروبوت يتذكر ما قيل، علينا حفظ سجل المحادثة وإرساله في كل مرة.
import os
from openai import OpenAI
client = OpenAI(api_key=os.environ.get("OPENAI_API_KEY"))
# قائمة لحفظ سجل المحادثة، تبدأ بتعليمات النظام
chat_history = [
{"role": "system", "content": "أنت مساعد برمجي خبير في لغة Python."}
]
def ask_chatbot(question):
# إضافة سؤال المستخدم إلى السجل
chat_history.append({"role": "user", "content": question})
response = client.chat.completions.create(
model="gpt-3.5-turbo",
messages=chat_history
)
# استخلاص إجابة المساعد
assistant_reply = response.choices[0].message.content
# إضافة إجابة المساعد إلى السجل للمحادثات القادمة
chat_history.append({"role": "assistant", "content": assistant_reply})
return assistant_reply
# بدء المحادثة التفاعلية
print("المساعد: مرحبًا! أنا مساعد Python الخاص بك. كيف يمكنني مساعدتك اليوم؟ (اكتب 'خروج' للإنهاء)")
while True:
user_input = input("أنت: ")
if user_input.lower() in ["خروج", "exit"]:
print("المساعد: إلى اللقاء!")
break
reply = ask_chatbot(user_input)
print(f"المساعد: {reply}")
جرب أن تسأله: “ما هي أفضل مكتبة لعمل رسوم بيانية؟” ثم اسأله: “وكيف أثبت المكتبة التي ذكرتها؟” ستجد أنه يتذكر إجابته السابقة بسبب إرسالنا لسجل المحادثة chat_history في كل مرة.
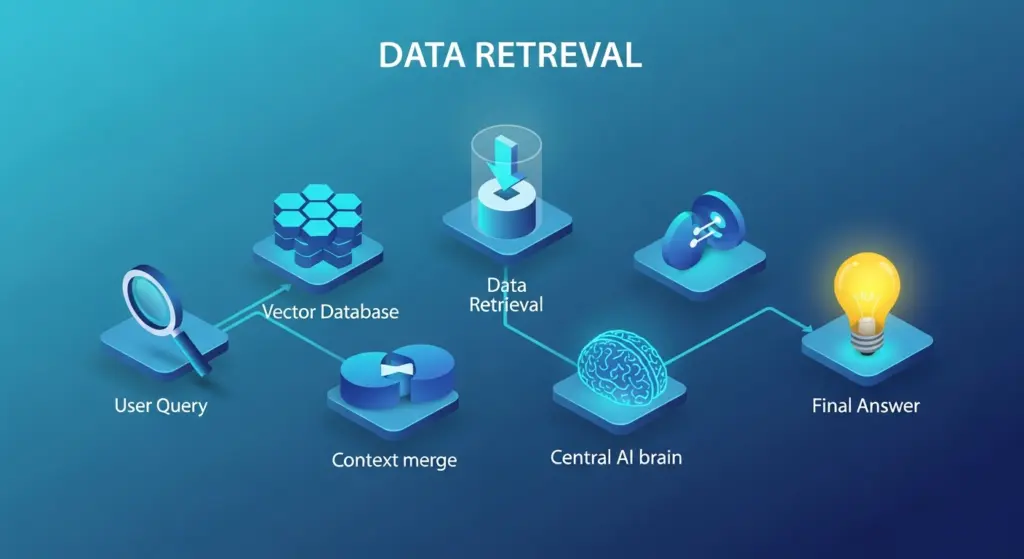
الخطوة 4 (متقدم): تزويد النموذج بمعرفة خارجية (RAG)
ماذا لو أردنا أن يجيب الـ Chatbot على أسئلة من وثائقنا الخاصة (ملفات PDF، قواعد بيانات) التي لم يتدرب عليها النموذج؟ هنا يأتي دور تقنية Retrieval-Augmented Generation (RAG).
الفكرة بسيطة وتتبع استراتيجية: “ابحث أولًا، ثم أجب”.
- الاسترداد (Retrieval): عندما يسأل المستخدم سؤالًا، نبحث أولًا في مستنداتنا المحلية عن الفقرات أو الأجزاء الأكثر صلة بالسؤال. (في التطبيقات الحقيقية، نستخدم تقنيات مثل “التضمين” (Embeddings) و”قواعد البيانات المتجهية” (Vector DBs) لهذا الغرض).
- التعزيز (Augmentation): نأخذ النصوص التي وجدناها ونضيفها إلى سياق السؤال الأصلي.
- التوليد (Generation): نرسل السؤال الأصلي مع السياق المعزز إلى الـ LLM ليقوم بصياغة إجابة طبيعية بناءً على المعلومات التي قدمناها له.
لنفترض أن لدينا ملف knowledge.txt يحتوي على معلومات عن شركتنا:
شركة الحلول الذكية هي شركة فلسطينية تأسست عام 2020. نحن متخصصون في بناء تطبيقات الويب باستخدام React و Django. يقع مقرنا الرئيسي في مدينة رام الله.الآن، لنبني نظام RAG بسيط:
# ... (كود الاتصال بـ OpenAI كما في السابق) ...
# 1. تحميل قاعدة المعرفة
with open('knowledge.txt', 'r', encoding='utf-8') as f:
knowledge_base = f.read()
def simple_retriever(query):
# هذا مجرد مثال بسيط جدًا للبحث. في الواقع نستخدم تقنيات أكثر تعقيدًا.
# هنا سنعيد قاعدة المعرفة كاملة إذا كانت كلمة "شركة" أو "مقر" موجودة في السؤال.
if "شركة" in query or "مقر" in query:
return knowledge_base
return ""
def ask_rag_chatbot(question):
# 1. الاسترداد (Retrieval)
retrieved_context = simple_retriever(question)
# بناء الـ Prompt للنموذج
prompt = f"""
استخدم المعلومات التالية فقط للإجابة على سؤال المستخدم.
إذا كانت المعلومة غير موجودة في "المعلومات"، قل بوضوح "لا أملك هذه المعلومة في قاعدة بياناتي".
المعلومات:
---
{retrieved_context}
---
سؤال المستخدم: {question}
"""
# 2. التعزيز والتوليد (Augmentation & Generation)
response = client.chat.completions.create(
model="gpt-3.5-turbo",
messages=[
{"role": "system", "content": "أنت مساعد متخصص في الإجابة على أسئلة حول شركة الحلول الذكية بناءً على معلومات محددة."},
{"role": "user", "content": prompt}
]
)
return response.choices[0].message.content
# --- جرب الآن ---
user_question = "أين يقع مقر شركتكم؟"
answer = ask_rag_chatbot(user_question)
print(f"السؤال: {user_question}\nالإجابة: {answer}\n")
user_question_2 = "ما هي عاصمة فرنسا؟"
answer_2 = ask_rag_chatbot(user_question_2)
print(f"السؤال: {user_question_2}\nالإجابة: {answer_2}")
نصيحة من أبو عمر: تقنية RAG هي من أقوى الأدوات في جعبتك. تسمح لك ببناء تطبيقات ذكاء اصطناعي مخصصة دون الحاجة إلى تكاليف الـ Fine-tuning الباهظة، مع ضمان أن الإجابات تستند إلى مصادر موثوقة أنت تحددها، مما يقلل بشكل كبير من “هلوسات” النموذج.
الجانب المظلم: الأخلاقيات، التحيز، والهلوسات
مع كل هذه القوة تأتي مسؤولية كبيرة. بما أن هذه النماذج تدربت على الإنترنت، فقد تعلمت كل التحيزات الموجودة في مجتمعاتنا. بالإضافة إلى ذلك، فإنها قد “تهلوس” (Hallucinate)، أي أنها تخترع حقائق أو معلومات بثقة تامة.
كمطورين، من واجبنا أن نكون واعين لهذه المشاكل. إليك بعض الإجراءات التي يمكنك اتخاذها:
- التوجيه عبر الـ Prompt: يمكنك أن تطلب من النموذج صراحةً في الـ
System Promptأن يكون محايدًا، ويتجنب التحيز، ويعترف عندما لا يعرف الإجابة. - استخدام RAG: الاعتماد على مصادر بياناتك الموثوقة (عبر RAG) هو أفضل طريقة للحد من الهلوسة وضمان دقة المعلومات.
- الفلترة والمراجعة: لا تثق بالمخرجات ثقة عمياء. قم بوضع طبقات فلترة لمراجعة المحتوى الذي يتم توليده، خاصة في التطبيقات التي تواجه المستخدم مباشرة.
- الشفافية: كن واضحًا مع المستخدمين بأنهم يتفاعلون مع نظام ذكاء اصطناعي قد يرتكب أخطاء.
خلاصة أبو عمر: نصائح من القلب للمستقبل
يا جماعة، نحن نعيش في عصر مذهل. نماذج اللغة الكبيرة ليست مجرد “موضة” عابرة، بل هي تحول جذري في كيفية تفاعلنا مع الآلات وبناء البرمجيات. رحلتنا اليوم غطت الكثير:
- فهمنا أن سحر الـ LLMs يكمن في معمارية الـ Transformers وآلية الانتباه.
- تعلمنا أن ذاكرة الـ Chatbot هي مسؤوليتنا كمطورين من خلال إدارة السياق.
- اكتشفنا أن هندسة الأوامر (Prompt Engineering) هي مفتاحك للحصول على أفضل النتائج.
- بنينا chatbot بسيطًا بـ Python، ثم طورناه باستخدام تقنية RAG القوية لجعله يجيب من مصادرنا الخاصة.
- تحدثنا عن أهمية الأخلاقيات والوعي بالتحيز والهلوسات.
نصيحتي الأخيرة لكم: لا تخافوا من التجربة والخطأ. أفضل طريقة لتعلم هذه التقنيات هي ببناء المشاريع. ابدأ بفكرة بسيطة، مساعد شخصي ينظم مهامك، أو chatbot يجيب على أسئلة حول هوايتك المفضلة. الكود الذي كتبناه اليوم هو مجرد بداية. ابدأ من هناك، عدّل عليه، واكتشف إمكانياته بنفسك. المستقبل بين أيديكم، فابنوه بحكمة وإبداع. والله ولي التوفيق.