يا أهلاً وسهلاً فيكم يا جماعة، معكم أبو عمر.
بتذكر مرة، قبل كم سنة، كنا شغالين على تطبيق موبايل لمطعم كبير عنده فروع وسلسلة توصيل ضخمة. التطبيق كان فيه كل شي: قائمة طعام بصورها ومكوناتها، ملف شخصي للمستخدم، سجل طلباته السابقة، ونظام نقاط ولاء. كنا مبسوطين وفخورين بالمشروع، لحد ما بلشت الشكاوى توصلنا من المستخدمين ومن صاحب المطعم نفسه: “التطبيق بطيء!”، “الصفحة الرئيسية بتضل تحمل”، “بستهلك كل باقة الإنترنت!”.
قعدنا كفريق، أنا وزملائي، نحلل المشكلة. فتحنا أدوات المطورين وبلشنا نراقب الشبكة (Network Tab)، وهون كانت الصدمة. عشان نعرض الصفحة الرئيسية للمستخدم، اللي فيها اسمه ونقاط الولاء تبعته، كنا نبعت طلب لـ API Endpoint اسمه /api/v1/users/{userId}. المشكلة إنه هاد الـ Endpoint كان يرجع “كل” إشي بيعرفه عن المستخدم: اسمه، إيميله، تاريخ ميلاده، كل عناوين التوصيل اللي حفظها، وسجل طلباته الكامل من أول يوم استخدم فيه التطبيق! إحنا كل اللي كنا محتاجينه هو بس حقلين: الاسم والنقاط. بس كنا مجبورين نحمّل كل هالمعلومات الهائلة، اللي أغلبها ما رح نستخدمه أبدًا في هاي الشاشة. كانت هاي أول مرة أواجه فيها وحش الـ “Over-fetching” وجهًا لوجه.
ولما كنا بدنا نعرض صفحة سجل الطلبات، كانت القصة بالعكس. كنا نطلب قائمة الطلبات من /api/v1/users/{userId}/orders. هاي بترجعلنا قائمة فيها أرقام الطلبات وتاريخها. بس عشان نعرض تفاصيل كل طلب (زي أسماء الوجبات وصورها)، كنا نضطر نبعت طلب API جديد “لكل طلب” في القائمة! يعني لو المستخدم عنده 10 طلبات، كنا نبعت 11 طلب API (واحد عشان يجيب قائمة الطلبات، و10 عشان يجيب تفاصيل كل طلب). هاد الوحش الثاني، اللي اسمه “Under-fetching”، كان يقتل أداء التطبيق ويخلي تجربة المستخدم سيئة للغاية. حسينا حالنا محبوسين في جحيم: يا منجيب كل إشي، أو منضل نطلب كمان وكمان. لحد ما سمعنا عن حل كان لسا جديد وقتها، اسمه GraphQL.
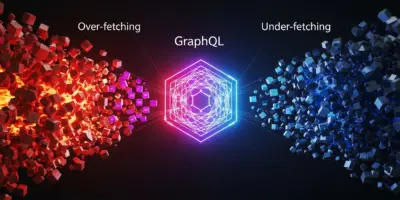
جحيم الـ API التقليدية: Over-fetching و Under-fetching
قبل ما نحكي عن الحل، خلينا نفصّل أكتر في المشكلتين اللي واجهتنا، واللي بتواجه أغلب المطورين اللي بيستخدموا REST APIs بالطريقة التقليدية.
المشكلة الأولى: الجلب الزائد (Over-fetching)
ببساطة، الـ Over-fetching بيصير لما الواجهة الأمامية (Frontend) تطلب بيانات من السيرفر، والسيرفر يرجعلها بيانات أكتر بكتير من اللي هي محتاجاه فعلاً. زي قصة تطبيق المطعم، كنا محتاجين بس اسم المستخدم ونقاطه، بس استلمنا كل تاريخ حياته على التطبيق.
مثال عملي (REST API):
تخيل عنا Endpoint اسمه /api/posts/1 بيرجع تفاصيل مقال معين. الواجهة الأمامية بدها تعرض بس عنوان المقال واسم الكاتب في قائمة المقالات.
الطلب:
GET /api/posts/1الاستجابة اللي بتوصلنا (Over-fetching):
{
"id": 1,
"title": "مقدمة في الذكاء الاصطناعي",
"content": "هنا محتوى المقال كاملاً... نص طويل جداً...",
"publishedAt": "2023-10-27T10:00:00Z",
"author": {
"id": "user-123",
"name": "أبو عمر",
"bio": "مبرمج فلسطيني خبير في الذكاء الاصطناعي...",
"avatarUrl": "https://example.com/avatar.jpg"
},
"comments": [
{ "commentId": 1, "text": "مقال رائع!" },
{ "commentId": 2, "text": "شكرًا للمعلومات القيمة" }
]
}كل اللي كنا محتاجينه هو title و author.name. بس بدل هيك، حمّلنا المحتوى كامل، وتفاصيل الكاتب، وكل التعليقات. هاد إهدار كبير للموارد، خصوصًا على شبكات الموبايل البطيئة.
المشكلة الثانية: الجلب الناقص (Under-fetching)
هاي المشكلة هي الوجه الآخر للعملة. بتصير لما الـ Endpoint الواحد ما يرجّع كل البيانات اللي بنحتاجها، فبنضطر نعمل طلبات إضافية عشان نكمل الصورة. هاي الظاهرة مشهورة باسم “مشكلة N+1”.
مثال عملي (REST API):
تخيل بدنا نعرض صفحة فيها قائمة بآخر 5 مقالات، وتحت كل مقال بدنا نعرض أسماء المعلقين عليه.
- الطلب الأول: نجيب قائمة المقالات.
GET /api/posts?limit=5 - الطلبات الإضافية (N requests): لكل مقال من الخمسة، بدنا نعمل طلب جديد عشان نجيب التعليقات الخاصة فيه.
GET /api/posts/1/comments GET /api/posts/2/comments GET /api/posts/3/comments GET /api/posts/4/comments GET /api/posts/5/comments
هون عملنا 1 (للمقالات) + 5 (للتعليقات) = 6 طلبات API عشان نعرض صفحة واحدة. تخيل لو القائمة فيها 20 مقال! هاد بيخلق تعقيد في كود الواجهة الأمامية وبطء شديد في تحميل الصفحة.
طوق النجاة: مقدمة إلى GraphQL
هون بيجي دور GraphQL، اللي طورتها فيسبوك داخليًا عام 2012 ونشرتها للعالم في 2015 عشان تحل هاي المشاكل بالزبط. GraphQL مش فريمورك ولا مكتبة، هي “لغة استعلام للـ APIs” (Query Language for APIs)، ومجموعة أدوات لتشغيل هاي الاستعلامات على سيرفرك.
الفكرة عبقرية وبسيطة: بدل ما يكون عنا endpoints كتير وكل واحد بيرجع شكل بيانات ثابت، بيكون عنا endpoint واحد فقط (عادة /graphql). الواجهة الأمامية بتبعت لهذا الـ endpoint “استعلام” (Query) بيوصف شكل البيانات اللي هي محتاجاها بالضبط، لا أكتر ولا أقل. والسيرفر بيرجع استجابة JSON بنفس شكل الاستعلام المطلوب.
كيف تحل GraphQL المشكلتين؟
خلينا نرجع لأمثلتنا السابقة ونشوف كيف GraphQL بتتعامل معها.
حل مشكلة الـ Over-fetching
بدل ما نطلب /api/posts/1 وناخذ كل شي، مع GraphQL بنكتب استعلام بنحدد فيه الحقول اللي بدنا إياها بالزبط.
الاستعلام (اللي بتبعته الواجهة الأمامية):
query GetPostTitleAndAuthor {
post(id: "1") {
title
author {
name
}
}
}الاستجابة اللي بتوصلنا (مثالية):
{
"data": {
"post": {
"title": "مقدمة في الذكاء الاصطناعي",
"author": {
"name": "أبو عمر"
}
}
}
}لاحظ كيف الاستجابة بتشبه تمامًا شكل الاستعلام. حصلنا على اللي بدنا إياه بالضبط. لا بيانات زائدة، لا إهدار للموارد. شغل نظيف ومرتب.
حل مشكلة الـ Under-fetching (مشكلة N+1)
مع GraphQL، بنقدر نطلب البيانات المترابطة (nested data) في استعلام واحد فقط. بدل ما نعمل 6 طلبات عشان نجيب المقالات وتعليقاتها، بنعمل طلب واحد بس.
الاستعلام:
query GetPostsWithComments {
posts(limit: 5) {
title
comments {
author {
name
}
text
}
}
}هذا الاستعلام بيحكي للسيرفر: “أعطيني آخر 5 مقالات، ولكل مقال بدي العنوان والتعليقات، ولكل تعليق بدي اسم كاتبه والنص تبعه”. كل هذا في طلب واحد!
السيرفر (إذا كان مكتوب صح) راح يفهم هذا الاستعلام، ويجيب كل البيانات بكفاءة من قاعدة البيانات (مثلًا باستخدام JOINs أو Dataloader pattern)، ويرجعها في استجابة واحدة متكاملة. هيك بنكون قضينا على مشكلة الـ N+1 من جذورها.
نصائح عملية من خبرة أبو عمر
الانتقال لـ GraphQL كان نقلة نوعية في مشاريعنا، بس الطريق ما كان مفروش بالورود دائمًا. هاي شوية نصائح من القلب، تعلمتها بالطريقة الصعبة أحيانًا:
-
ابدأ بفهم الـ Schema
قلب أي سيرفر GraphQL هو الـ Schema. هي العقد اللي بين الواجهة الخلفية والواجهة الأمامية. قبل ما تكتب أي كود، استثمر وقت في تصميم Schema واضح وقوي بيوصف كل أنواع البيانات والعلاقات بينها في نظامك. الـ Schema الجيد هو أساس كل شي.
-
GraphQL لا تعني التخلي عن REST
GraphQL مش رصاصة فضية بتحل كل المشاكل. REST API ما زالت ممتازة جدًا في حالات كثيرة، خصوصًا للـ APIs العامة البسيطة أو للتواصل بين الخدمات الداخلية (microservices). ما في داعي تعمل rewrite لكل مشروعك. ممكن تبدأ بإضافة GraphQL endpoint جنب الـ REST APIs الموجودة عندك، وتستخدمه للميزات الجديدة أو للشاشات المعقدة.
-
فكر في الـ Caching بشكل مختلف
مع REST، كان الـ Caching سهل نسبيًا. كل URL له استجابة ممكن نعملها cache. مع GraphQL، كل الطلبات بتروح على نفس الـ endpoint (
/graphql)، فالـ HTTP caching التقليدي ما بينفع. بدك تعتمد على مكتبات متخصصة في الـ Caching زي Apollo Client أو Relay اللي بتعمل cache للبيانات بناءً على أنواعها والـ IDs تبعتها، وهذا موضوع كبير بحد ذاته. -
استخدم الأدوات المتاحة
من أجمل الأشياء في عالم GraphQL هو الأدوات الرائعة. أدوات زي GraphiQL أو Apollo Studio Explorer بتعطيك واجهة تفاعلية لاستكشاف الـ Schema وكتابة الاستعلامات وتجربتها مباشرة على السيرفر. هاي الأدوات بتسرّع عملية التطوير بشكل لا يصدق وبتخلي التعاون بين فريق الـ Frontend والـ Backend أسهل بكتير.
الخلاصة: متى تستخدم GraphQL؟
زي ما بنحكي دايماً، لكل مقام مقال. GraphQL مش دايماً الحل الأفضل، بس هي حل عبقري لما تكون الظروف مناسبة.
GraphQL بتلمع وبتظهر قوتها الحقيقية في السيناريوهات التالية:
- تطبيقات الموبايل: اللي بتكون فيها سرعة الشبكة واستهلاك البيانات عوامل حاسمة.
- الواجهات الأمامية المعقدة (Complex UIs): مثل لوحات التحكم (Dashboards) اللي بتعرض بيانات من مصادر متعددة في شاشة واحدة.
- الفرق الكبيرة اللي فيها فريق Frontend وفريق Backend منفصلين: الـ Schema بيصير هو لغة التواصل المشتركة وبيقلل الاعتمادية بينهم.
في النهاية، الانتقال لـ GraphQL كان من أفضل القرارات التقنية اللي أخذناها في مشاريعنا. أعطى قوة وسيطرة للواجهة الأمامية، حسّن الأداء بشكل ملحوظ، وخلّى عملية تطوير الميزات الجديدة أسرع وأكثر متعة. إذا كنت لسا بتعاني من جحيم الـ Over-fetching والـ Under-fetching، بنصحك بشدة تعطي GraphQL فرصة. يمكن تكون هي طوق النجاة اللي فريقك محتاجه. 👍